from src.utils.helper_plot import get_minimal_distance_factors
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# constants
FOLDER_INTERIM = os.environ.get('DIR_DATA_INTERIM')
DATA_CRIME_CATEGORY = 'df_category.csv'
DATA_POP = 'df_pop.csv'
FIG_SIZE = (30, 15)
TITLE_SIZE = 40
LABEL_SIZE = (20,20)
TICK_SIZE = 15
PALETTE = 'Set2'
df_category = pd.read_csv(filepath_or_buffer=FOLDER_INTERIM + "/" + DATA_CRIME_CATEGORY,
parse_dates=["Outcome Date"])
df_pop = pd.read_csv(filepath_or_buffer=FOLDER_INTERIM + "/" + DATA_POP)
Reshape the data so it is in the right format for plotting.
# aggregate to ward level
## for barplot and kernel-density plot
df_ward = df_category.groupby(by=["Outcome Year", "Outcome Month", "Ward Name", "Population"]).agg(func={"Crime Incidences": 'sum'}).reset_index()
df_ward["Crime Rate"] = df_ward["Crime Incidences"] / df_ward["Population"]
## for time-series
df_ward_ts = df_category.groupby(by=["Outcome Date", "Ward Name", "Population"]).agg(func={"Crime Incidences": 'sum'}).reset_index()
df_ward_ts["Crime Rate"] = df_ward_ts["Crime Incidences"] / df_ward_ts["Population"]
# aggregate to Camden level
## for barplot and kernel-density plot
df_camden = df_ward.groupby(by=["Outcome Year", "Outcome Month"]).agg(func={"Crime Incidences": 'sum', "Population": 'sum'}).reset_index()
df_camden["Crime Rate"] = df_camden["Crime Incidences"] / df_camden["Population"]
## for time-series
df_camden_ts = df_ward_ts.groupby(by=["Outcome Date"]).agg(func={"Crime Incidences": 'sum', "Population": 'sum'}).reset_index()
df_camden_ts["Crime Rate"] = df_camden_ts["Crime Incidences"] / df_camden_ts["Population"]
5.2. Explore Crime by Location¶
In this section, we explore further general crime rates by at Camden and its corresponding wards by looking at the following plots:
Boxplot - to understand the range of values for crime incidences, including the percentiles such as 25th, 50th and 75th percentiles.
Kernel density - to understand how our data is distributed across number of crime incidences.
Line plot - to understand how crime rates have evolved over time
5.2.1. Crime in Camden¶
In this section, we focus on looking at crime rates in the higher-level Camden local authority.
5.2.1.1. Understanding range of values¶
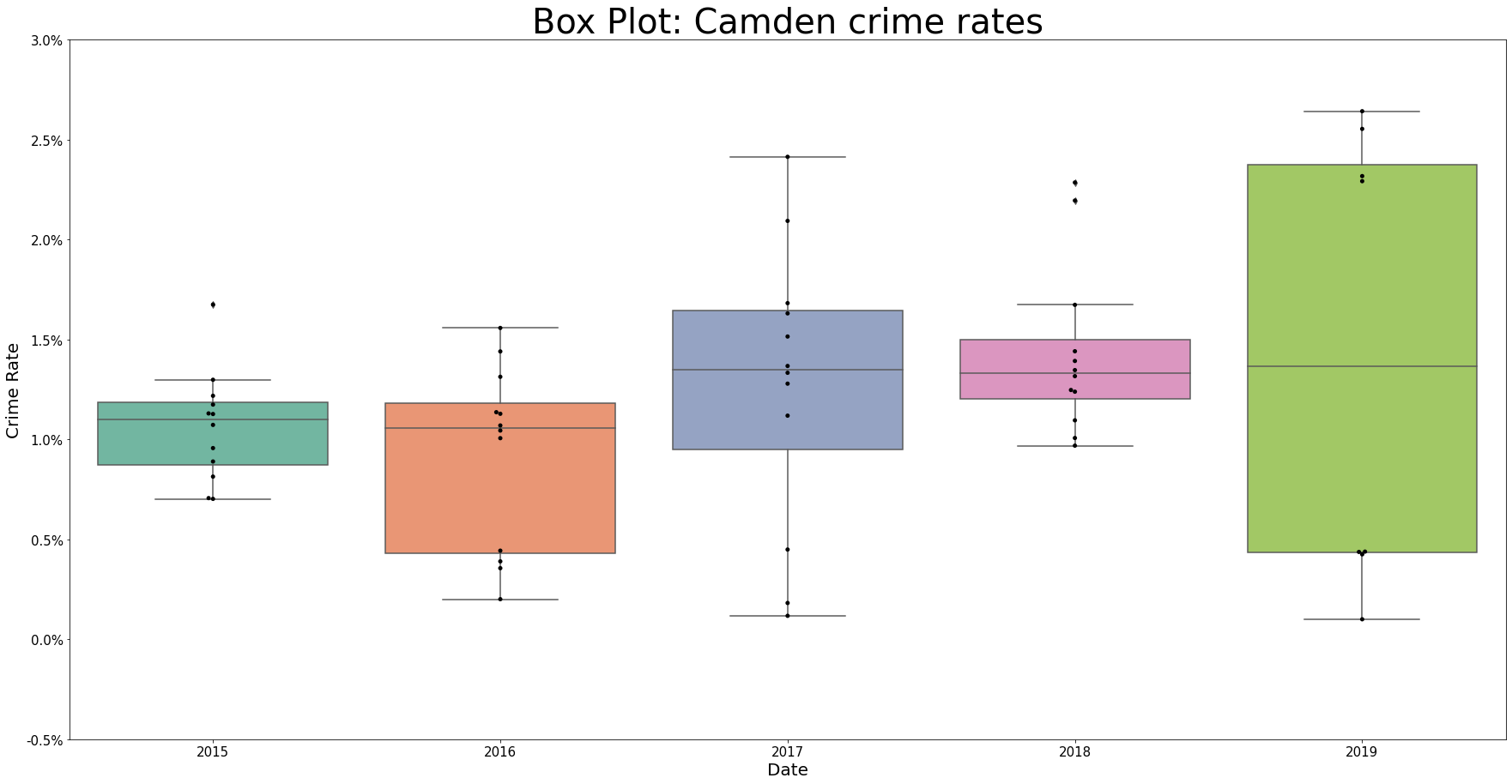
We see that the spread of our monthly crime rates for Camden vary quite differently across years. For 2015 and 2018, the range is quite narrow whereas for other years, the rates can jump between relatively high and low rates across each month.
Of most interest in 2019 where we have rates bunched up around 0.18% and 0.04% but no monthly rates in between. This year is also the year where the percentage point interquartile range is largest.
# set size of plot
fig, ax = plt.subplots(figsize=FIG_SIZE)
# plot
ax = sns.boxplot(x="Outcome Year", y="Crime Rate", data=df_camden, palette=PALETTE)
ax = sns.swarmplot(x="Outcome Year", y="Crime Rate", data=df_camden, color='black')
# adjust y-axis values to percentages for easier reading - https://stackoverflow.com/a/63755285/13416265
ticks_loc = ax.get_yticks().tolist()
ticks_loc = [round(number=x * 100, ndigits=2) for x in ticks_loc]
ax.set_yticks(ax.get_yticks().tolist())
ax.set_yticklabels([f"{x}%" for x in ticks_loc])
ax.set_xlabel(xlabel="Date", fontsize=LABEL_SIZE[0])
ax.set_ylabel(ylabel="Crime Rate", fontsize=LABEL_SIZE[1])
ax.tick_params(labelsize=TICK_SIZE)
ax.set_title(label="Box Plot: Camden crime rates", fontsize=TITLE_SIZE)
Text(0.5, 1.0, 'Box Plot: Camden crime rates')
5.2.1.2. Understanding distribution of data¶
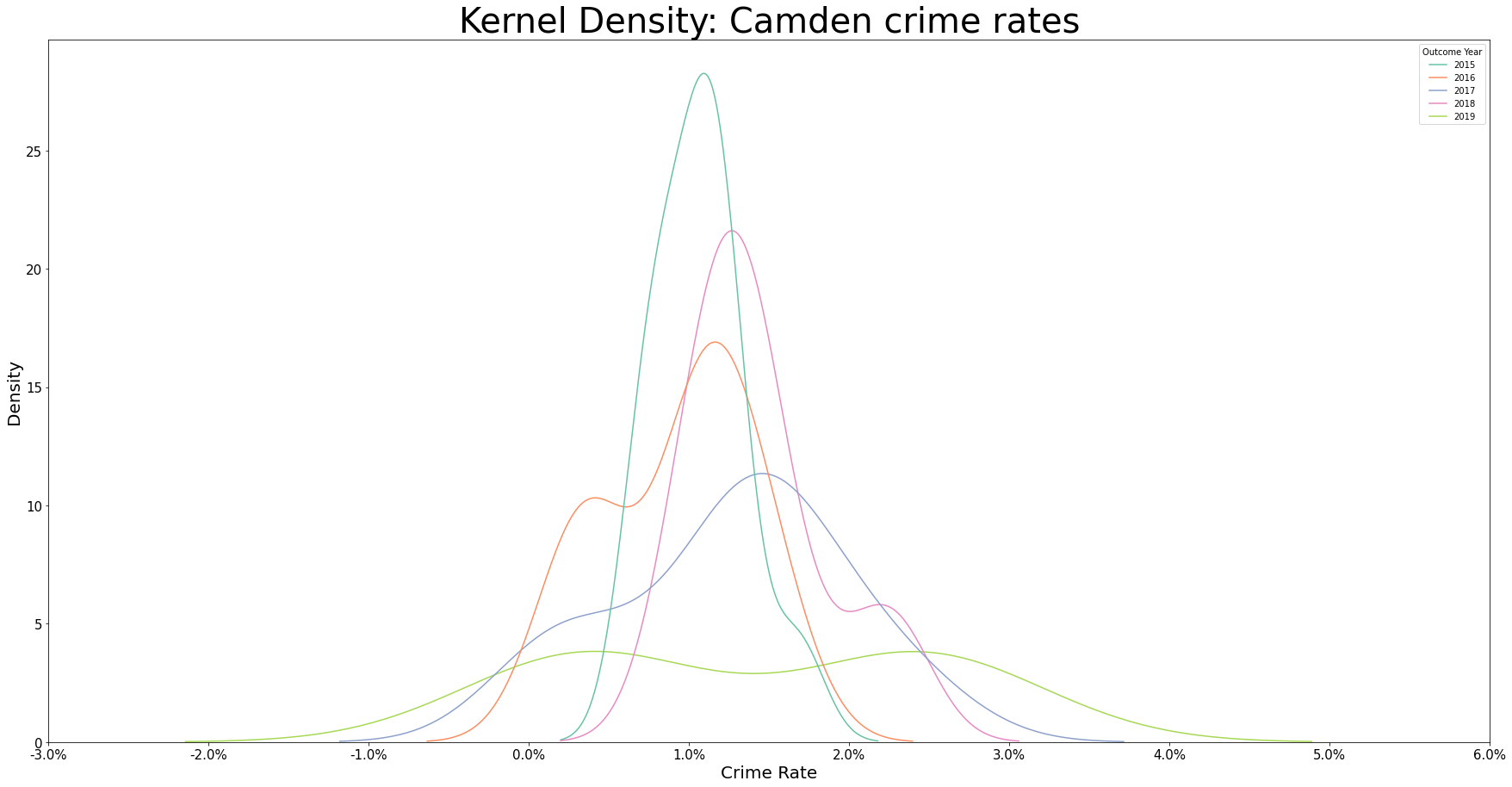
We see in the density plots below complimentary information to the boxplots earlier, namely that for 2015, the spread of crime rates are concentrated around a small range, as suggested by the narrow and tall shape; whereas for 2019, we have the spread of crime rates to be large, as suggested by the wide and short shape, with there being two peaks around the interquartile range.
Considered violin plot to replace the boxplot and kernel density plot but hard to see the median values.
# set size of plot
fig, ax = plt.subplots(figsize=FIG_SIZE)
# plot
sns.kdeplot(data=df_camden, x="Crime Rate", hue="Outcome Year", palette=PALETTE)
# adjust x-axis values to percentages for easier reading - https://stackoverflow.com/a/63755285/13416265
ticks_loc = ax.get_xticks().tolist()
ticks_loc = [round(number=x * 100, ndigits=2) for x in ticks_loc]
ax.set_xticks(ax.get_xticks().tolist())
ax.set_xticklabels([f"{x}%" for x in ticks_loc])
ax.set_xlabel(xlabel="Crime Rate", fontsize=LABEL_SIZE[0])
ax.set_ylabel(ylabel="Density", fontsize=LABEL_SIZE[1])
ax.tick_params(labelsize=TICK_SIZE)
ax.set_title(label="Kernel Density: Camden crime rates", fontsize=TITLE_SIZE)
Text(0.5, 1.0, 'Kernel Density: Camden crime rates')
5.2.1.3. Understanding evolution of crime rates over time¶
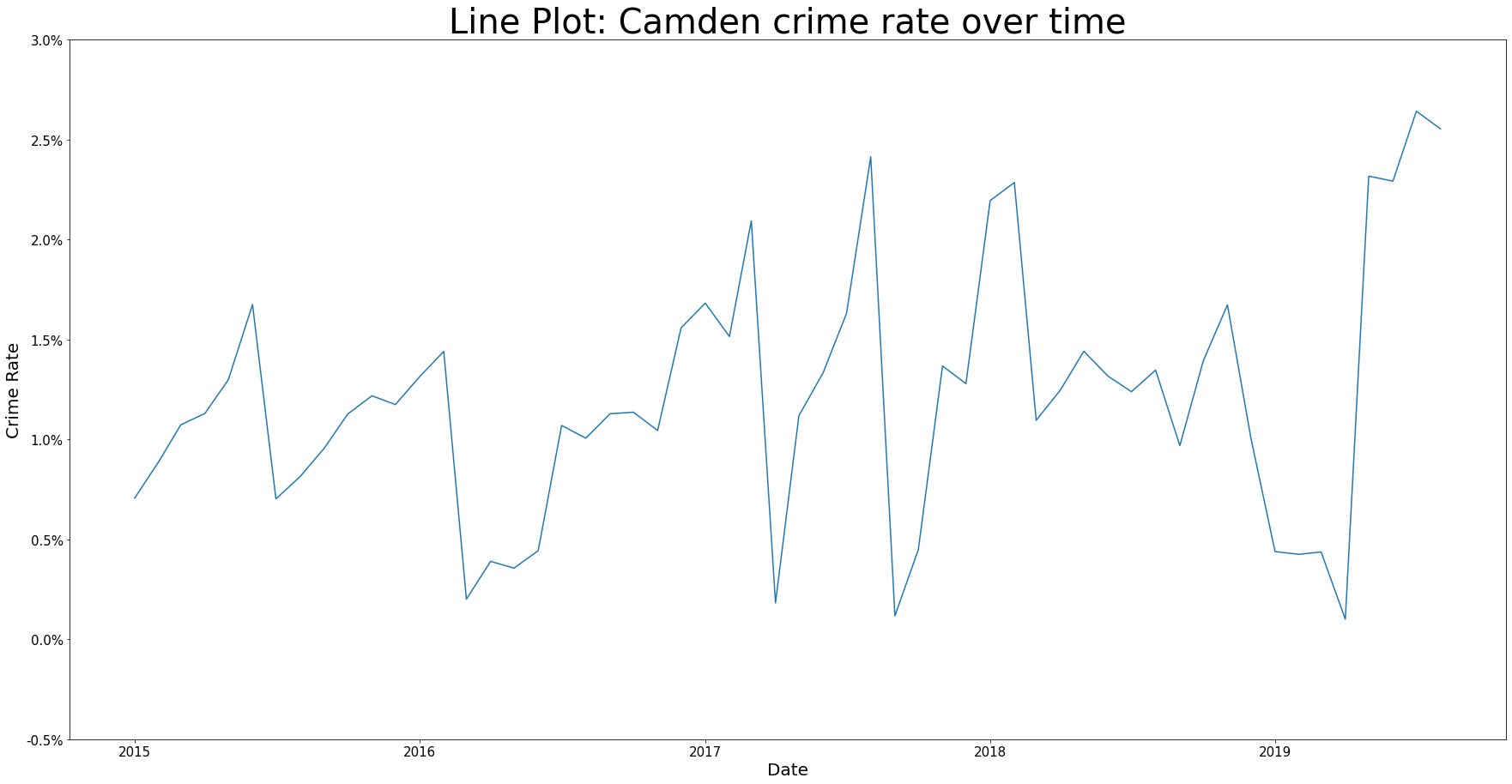
We see that generally, there is an upward trend in the crime rate from 2015 to 2019. However there is a lot of fluctuation and does not appear to be any recurring patterns between years so we are unlikely to see seasonal spikes or troughs in crime. There is an exception to this seasonal pattern though because we do spot in-year troughs of crime rates around Feb-Apr time.
fig, ax = plt.subplots(figsize=FIG_SIZE)
sns.lineplot(data=df_camden_ts, x="Outcome Date", y="Crime Rate", palette=PALETTE)
# adjust y-axis values to percentages for easier reading - https://stackoverflow.com/a/63755285/13416265
ticks_loc = ax.get_yticks().tolist()
ticks_loc = [round(number=x * 100, ndigits=2) for x in ticks_loc]
ax.set_yticks(ax.get_yticks().tolist())
ax.set_yticklabels([f"{x}%" for x in ticks_loc])
ax.set_xlabel(xlabel="Date", fontsize=LABEL_SIZE[0])
ax.set_ylabel(ylabel="Crime Rate", fontsize=LABEL_SIZE[1])
ax.tick_params(labelsize=TICK_SIZE)
ax.set_title(label="Line Plot: Camden crime rate over time", fontsize=TITLE_SIZE)
Text(0.5, 1.0, 'Line Plot: Camden crime rate over time')
5.2.2. Crime in Camden Wards¶
In this section, we focus on looking at crime rates in the lower-level Camden wards.
5.2.2.1. Understanding range of values¶
Similar to what was seen at the Local Authority-level of Camden, across all wards, the range of values for our crime rate is smallest during 2015 and largest for 2019, with years between this having different ranges.
fig, ax = plt.subplots(figsize=(30, 40))
ax = sns.boxplot(ax=ax, x="Crime Rate", y="Ward Name", data=df_ward, orient='h', palette='Set2', hue="Outcome Year", dodge=True)
ax.set_xticks(ax.get_xticks().tolist())
ax.set_xticklabels([f"{x}%" for x in ticks_loc])
ax.set_xlabel(xlabel="Crime Rate", fontsize=LABEL_SIZE[0])
ax.set_ylabel(ylabel="Ward Name", fontsize=LABEL_SIZE[1])
plt.setp(ax.get_legend().get_texts(), fontsize=TICK_SIZE)
plt.setp(ax.get_legend().get_title(), fontsize=LABEL_SIZE[0])
ax.tick_params(labelsize=TICK_SIZE)
ax.set_title(label="Bar Plot: Camden ward crime rate over time", fontsize=TITLE_SIZE)
Text(0.5, 1.0, 'Bar Plot: Camden ward crime rate over time')
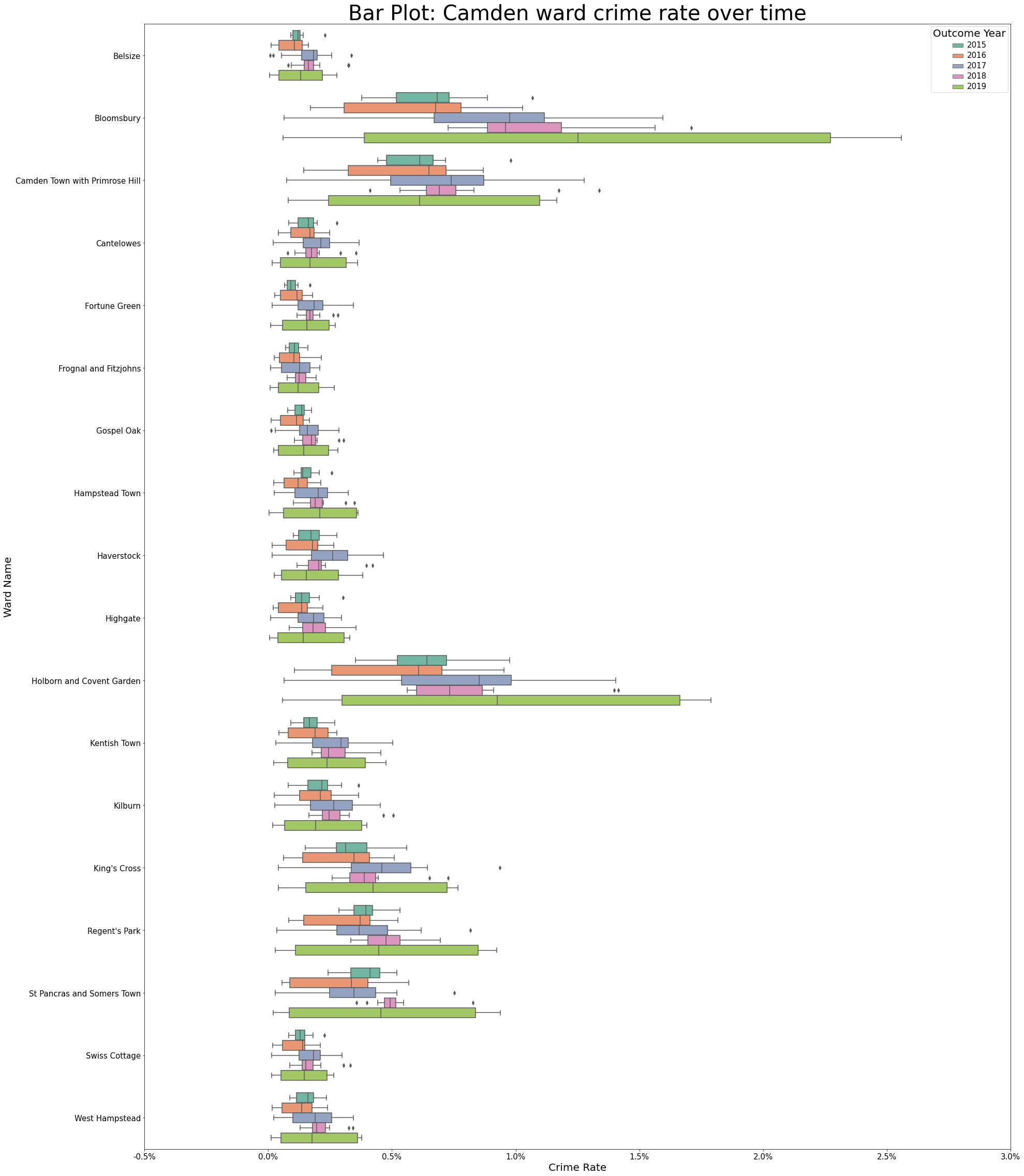
5.2.2.2. Understanding distribution of data¶
Similar to what was seen at the Local Authority-level of Camden, across all wards, we see below complimentary information to the boxplots earlier, namely that for 2015, the spread of crime rates are concentrated around a small range, as suggested by the narrow and tall shape; whereas for 2019, we have the spread of crime rates to be large, as suggested by the wide and short shape, with there being two peaks around the interquartile range.
# set size of plot
wards = df_ward["Ward Name"].unique()
rows, cols = get_minimal_distance_factors(n=len(wards))
fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=FIG_SIZE)
# plot
plt.suptitle(t="Kernel-Density: Crime Rates for each Camden ward", fontsize=TITLE_SIZE)
for ax, ward in zip(axes.flatten(), wards):
df = df_ward[df_ward["Ward Name"] == ward]
sns.kdeplot(ax=ax, data=df, x="Crime Rate", hue="Outcome Year", palette='Set2')
ax.set_title(label=f"{ward}")
# adjust x-axis values to percentages for easier reading - https://stackoverflow.com/a/63755285/13416265
ticks_loc = ax.get_xticks().tolist()
ticks_loc = [round(number=x * 100, ndigits=2) for x in ticks_loc]
ax.set_xticks(ax.get_xticks().tolist())
ax.set_xticklabels([f"{x}%" for x in ticks_loc])
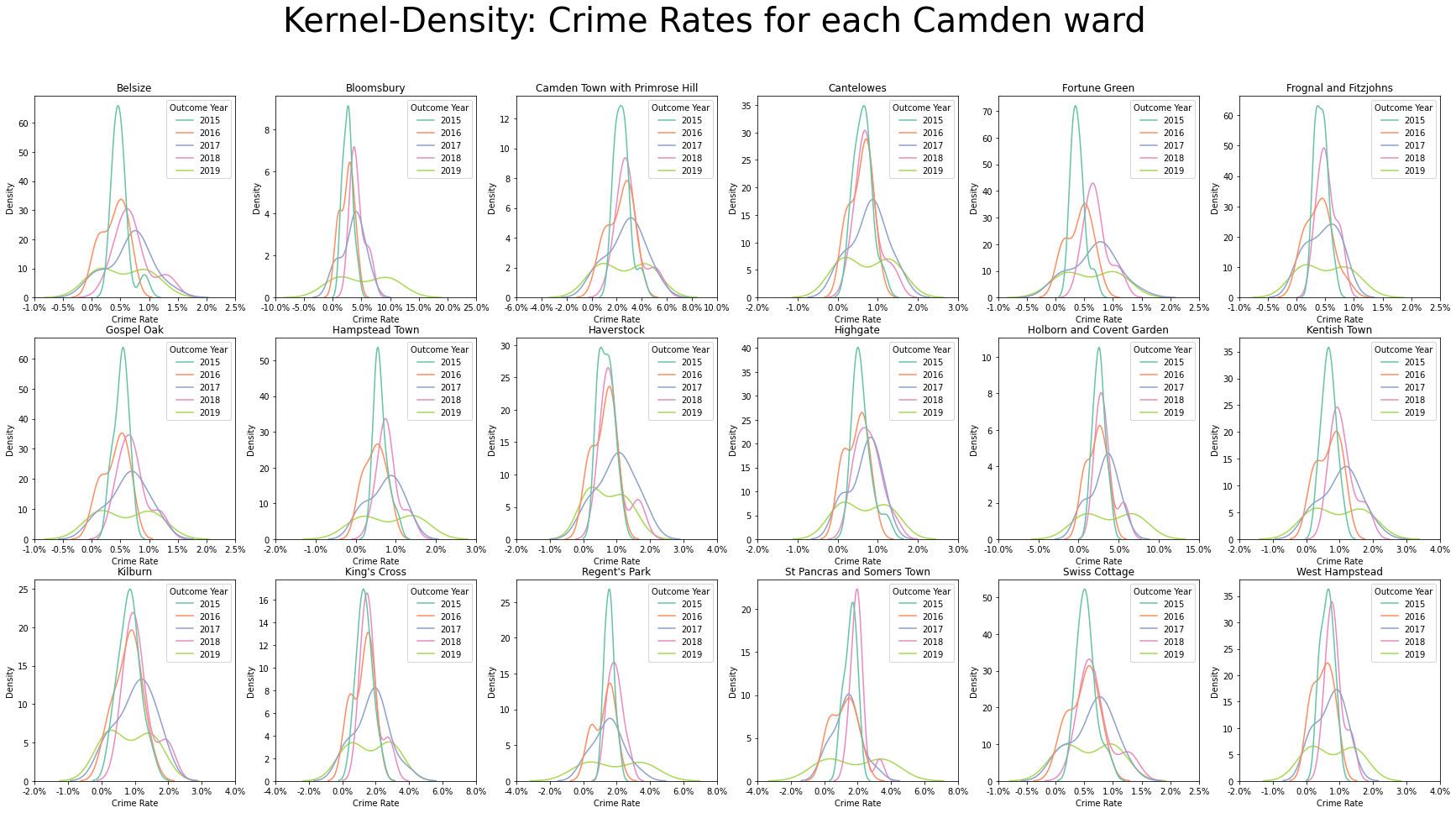
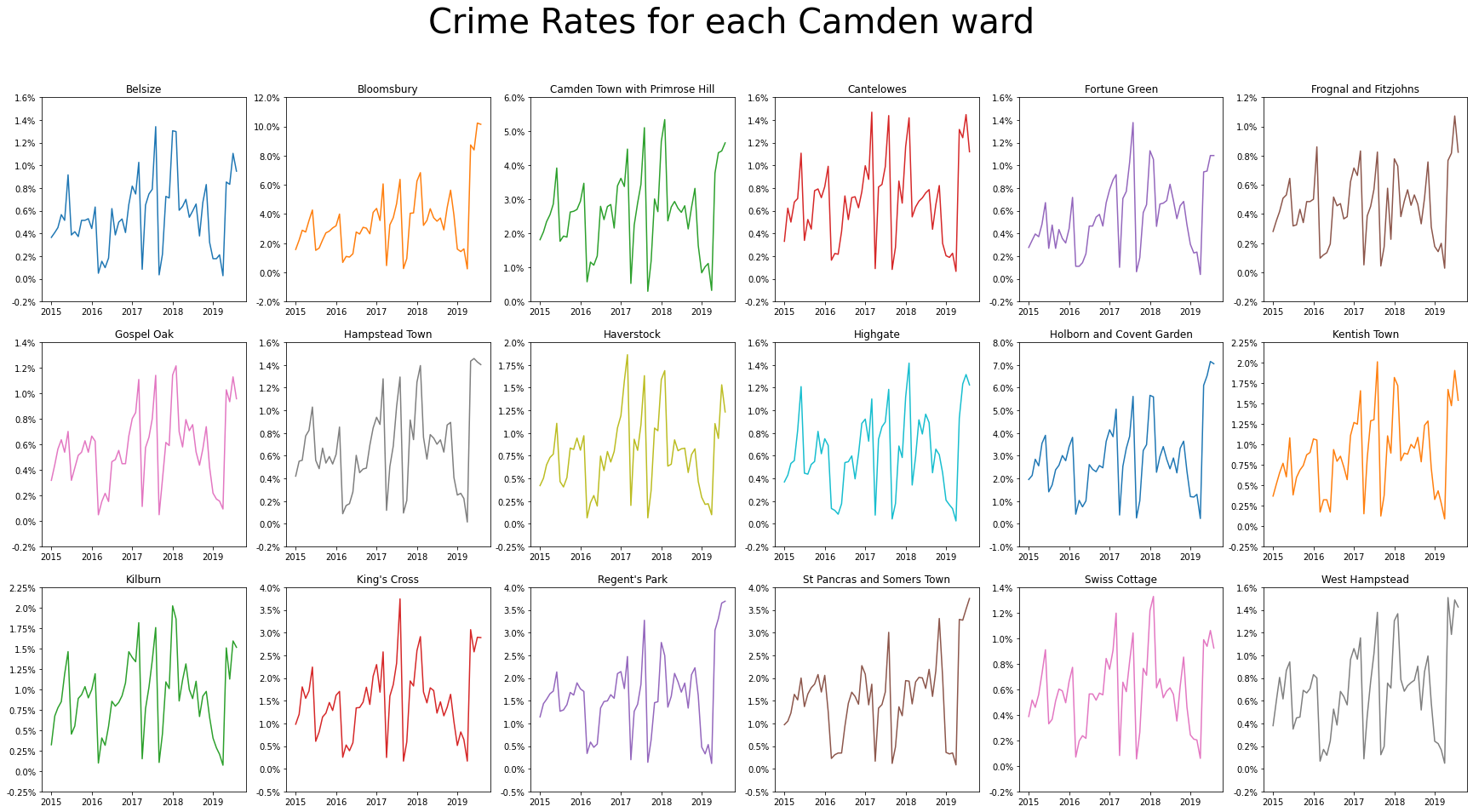
5.2.2.3. Understanding evolution of crime rates over time¶
Similar to what was seen at the Local Authority-level of Camden, across all wards, we see that crime rates have an upward trend. There is not much of a strong seasonal pattern also.
[StackOverflow - gboffi, 2018]
wards = df_ward_ts["Ward Name"].unique()
colours = plt.rcParams['axes.prop_cycle']()
fig, axes = plt.subplots(nrows=3, ncols=6, figsize=(30,15))
plt.suptitle(t="Crime Rates for each Camden ward", fontsize=TITLE_SIZE)
for ax, ward in zip(axes.flatten(), wards):
df = df_ward_ts[df_ward_ts["Ward Name"] == ward]
ax.plot("Outcome Date", "Crime Rate", data=df, **next(colours))
ticks_loc = ax.get_yticks().tolist()
ticks_loc = [round(number=x * 100, ndigits=2) for x in ticks_loc]
ax.set_yticks(ax.get_yticks().tolist())
ax.set_yticklabels([f"{x}%" for x in ticks_loc])
ax.set_title(label=f"{ward}")